Stability AI may be starting its very own redemption arc. After the disappointment that was SD3 Medium, they’ve come back swinging with the release of two new models that had been promised back in July: Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo.
“In June, we released Stable Diffusion 3 Medium, the first open release from the Stable Diffusion 3 series. This release didn’t fully meet our standards or our communities’ expectations,” Stability said in an official blog post. “After listening to the valuable community feedback, instead of a quick fix, we took the time to further develop a version that advances our mission to transform visual media.”
We generated a few images to try it out before rushing to write this breaking news—and the results were pretty, pretty good. Especially for a base model.
The SD 3.5 family is designed to run on consumer-grade systems—even low end by some standards—making advanced image generation more accessible than ever. And yes, they’ve heard the complaints about the previous version so this one promises to be a lot better—so much that their featured image is a woman lying on grass, a wry reference to the horrorshow that occurred earlier when presented with the same challenge.
Image: Stability AI
Another important aspect of this release is the new licensing model. Stable Diffusion 3.5 comes under a more permissive license, allowing both commercial and non-commercial use. Small businesses and people who make less than $1,000,000 in revenue from the tool can use and build on these models for free.
Those with a larger revenue must contact Stability to negotiate fees. By comparison, Black Forest Labs offers its lower-end Flux Schnell for free, its medium model Flux Dev free with non commercial use and its SOTA model Flux Pro is a closed source model. (For reference, Flux is generally considered the best open source image generator currently available—at least in the current post-SDXL era.)
What’s on the Table with Stable Diffusion 3.5?
Stability AI is releasing three versions of Stable Diffusion 3.5, all of which cater to different needs:
Stable Diffusion 3.5 Large: This is the big one, with 8 billion parameters designed to deliver top-notch image quality and tight prompt adherence. It’s made for professional use, particularly at a 1-megapixel resolution, but can handle a range of styles and visual formats.
Stable Diffusion 3.5 Large Turbo: For those who want to trade a little bit of quality for speed, this distilled version of the Large model is your go-to. It cranks out high-quality images in just four steps—unlike the normal SD3.5 which requires around 30 steps to generate a good quality image. It would be the equivalent to Flux Schell.
Stable Diffusion 3.5 Medium: Coming soon, this model has 2.5 billion parameters and is optimized for consumer hardware. It’s the middle ground for users who need solid performance at resolutions between 0.25 and 2 megapixels, without sacrificing ease of customization.
The models are much more flexible, allowing users to fine-tune them for specific creative needs. And if you’re worried about whether your consumer-grade GPU can handle this, Stability AI has your back. Our own tests show the Large Turbo spitting out images in about 40 seconds on a modest RTX 2060 with 6GB of VRAM.
The non quantized full-fat version needs over 3 minutes on the same lower end hardware, but that’s the price of quality.
Improvements Under the Hood
Stability AI is playing catch up against Flux, which is the go-to model for customizability. To improve user experience, Stability reimagined how SD 3.5 behaves. “In developing the models, we prioritized customizability to offer a flexible base to build upon. To achieve this, we integrated Query-Key Normalization into the transformer blocks, stabilizing the model training process and simplifying further fine-tuning and development,” Stability said.
In other words, you can tweak and refine these models much more easily than before, whether you’re an artist wanting to create custom styles or a developer looking to build an AI-powered application. Stability even shared a LoRA training guide to help things kick things off a lot faster.
LoRA (low rank adaptation) is a technique to fine tune models to specialize in a specific concept—be it a style, or a subject–without having to retrain the whole large base model.
Caption: The same generation without a LoRA vs using a LoRA to add more details. Image: Civitai
Of course, with flexibility comes some trade-offs. The model is now so creative that Stability warns that “prompts lacking specificity might lead to increased uncertainty in the output, and the aesthetic level may vary”
If you’re still on the fence about Stable Diffusion 3.5 and its “uncertainty” drives you off, here’s a bit of futureproofing for you—it supports “negative prompts,” meaning your prompt can include instructions not to do things. This is a massive boon for those who want to refine text and image generation without jumping through hoops.
It’s a nice addition for those who want a bit more control over their generations. Also, it seems pretty good at handling the good old SDXL style of prompting. In fact, in some ways, SD3.5’s prompting style is closer to MidJourney than Flux, allowing users to get creative without needing a degree in linguistics.
Beyond customization Stable Diffusion 3.5 moves forward in other areas:
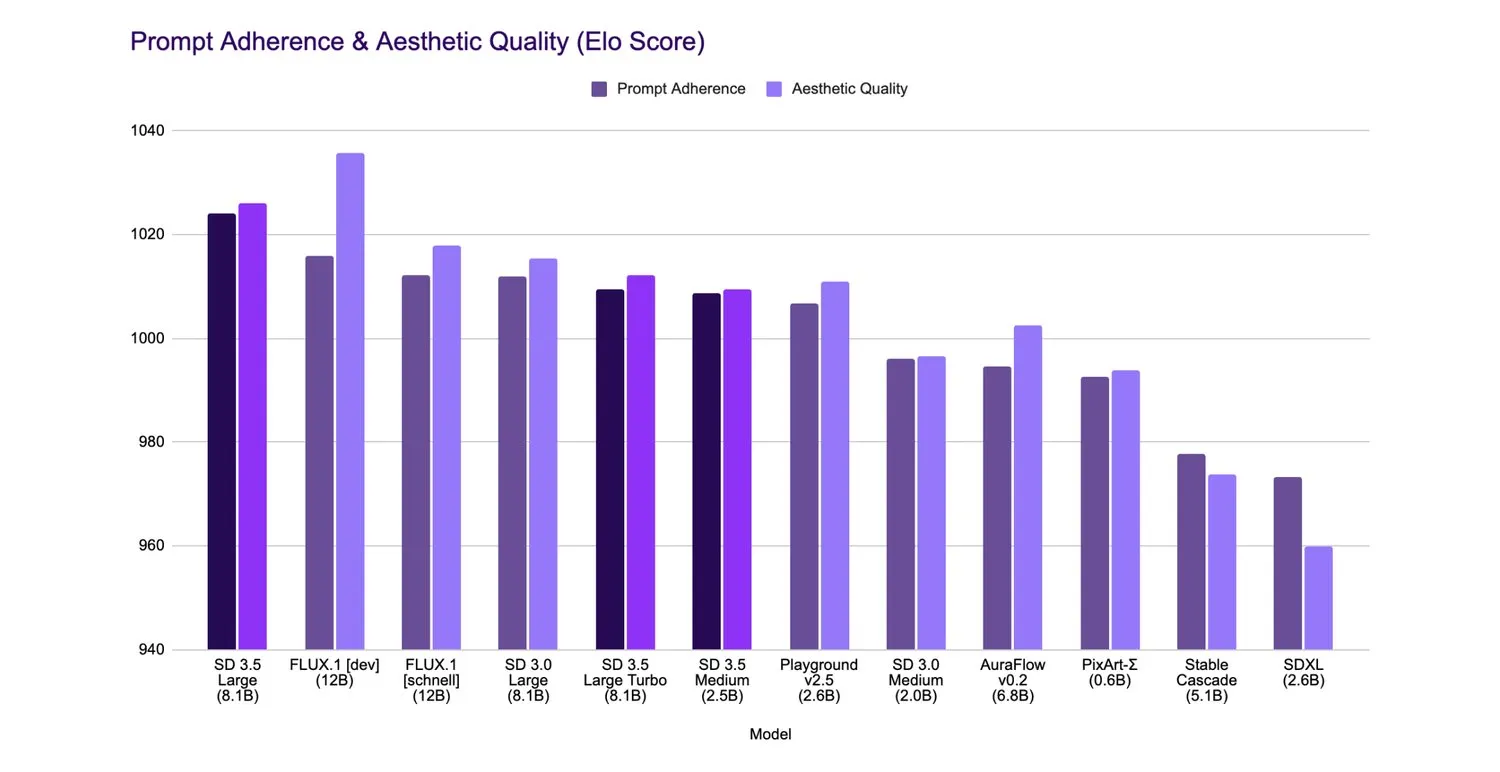
Prompt adherence: The Large model now rivals even much bigger models in terms of how well it follows user input, and it leads the pack in the world of image generators. So much that Stability assures SD 3.5 large beats Flux.1 Dev in terms of prompt adherence—still not in aesthetic quality, though.
Image: Stability AI
Image quality: We’re talking about generating images that stand up to some of the most resource-hungry models out there, without burning through your GPU’s memory. In Stability’s benchmarks, Flux.1 Dev is the king by a little bit, however, SD 3.5 Large is more efficient and less resource-heavy. Sd 3.5 Large Turbo is comparable to Flux.1 Schnell in both adherence and quality.
Style versatility: Whether you’re aiming for 3D renders, photorealistic images, line art, or painting styles, Stable Diffusion 3.5 can handle it. It handles a wider array of styles than Flux—at least in our quick tests.
And yes, it’s worth mentioning—it’s uncensored. SD3.5 Large can produce certain types of content, including nudity, without too much difficulty, though it’s not perfect. For better or worse, the model isn’t purposely restricted, so it offers users full creative freedom (though fine-tuning and some specific prompts may be required for best results).
This was heavily criticized when SD3 launched and was pointed out as one of the main reasons it failed so hard in anatomy comprehension. We could confirm its ability to generate NSFW imagery, however, the model is not on the same level as the best Flux finetunes but is comparable to the original Flux models.
But fair warning: as powerful as SD3.5 is, you NSFW Furry artists shouldn’t expect a Pony Diffusion Model anytime soon—or at all. The creator of the most popular and powerful NSFW model confirmed they are not interested in developing a SD3.5 finetune. Instead, they chose to build their models using Auraflow as a base. Once they are done, they may consider Flux.
For the tinkerers out there, ComfyUI now supports Stable Diffusion 3.5, allowing local inference with signature node-based workflows. There are plenty of workflow examples ready to go, and if you’re struggling with lower RAM but want to try the full SD3.5 experience, Comfy rolled out an experimental fp8-scaled model that lowers memory usage.
What’s Next?
On October 29, we’ll get our hands on Stable Diffusion 3.5 Medium, and not long after Stability promised to release Control Nets for SD 3.5.
ControlNets promise to bring advanced control features, tailored for professional use cases, and they could very well take the power of SD3.5 to the next level. If you want to know more about them, you can read a summary of our brief guide for SD 1.5. However, using controlents will let users do things like choosing their subject’s pose, play around with depth maps, reimagine a scene based on a scribble, and more.
Original Image vs Generation using a Controlnet to influence the subejct’s pose. Credit: Jose Lanz
So, is Stable Diffusion 3.5 a Flux Killer? Not quite, but it’s definitely starting to look like a contender. Some users will still nitpick, especially after the drama of the SD3 Medium flop. But with better anatomy handling, a clearer license, and significant improvements in prompt adherence and output quality, it’s hard to argue that this isn’t a big step forward. Stability AI is learning from past mistakes and moving toward a future where advanced AI tools are more accessible to all.
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.